
URL中井号的作用
扫描二维码
1. 井号在URL中指定的是页面中的一个位置
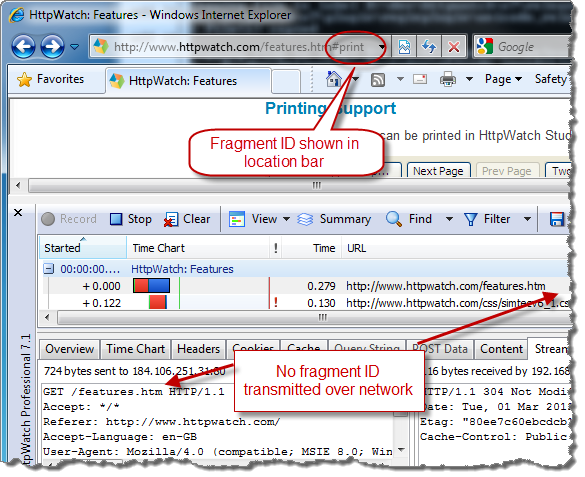
井号作为页面定位符出现在URL中,比如:
http://www.httpwatch.com/features.htm#print
此URL表示在页面features.htm中print的位置。浏览器读取这个URL后,会自动将print位置滚动至可视区域。

在页面上添加锚点的方法为:
<a name=”print”></a>
或使用
<div id=”print” >
2.井号后面的数据不会发送到HTTP请求中
当时使用类似HttpWatch工具时,你是无法在Http请求中找到井号后面的参数的,原因是井号后面的参数是针对浏览器起作用的而不是服务器端。
3. 任务位于井号后面的字符都是位置标识符
不管第一个井号后面跟的是什么参数,只要是在井号后面的参数一律看成是位置标识符。
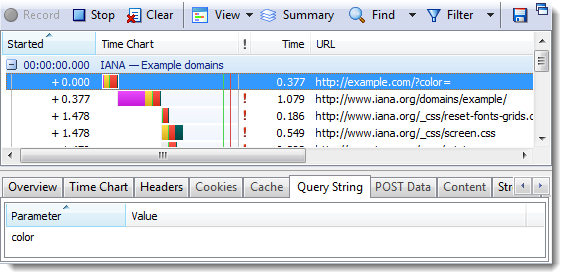
比如这样一个链接
http://example.com/?color=#ffff&shape=circle
后面跟的参数是颜色和形状,但是服务器却并不能理解URL中的含义。服务器接收到的只是:
4. 改变井号后面的参数不会触发页面的重新加载但是会留下一个历史记录
仅改变井号后面的内容,只会使浏览器滚动到相应的位置,并不会重现加载页面。
比如从
http://www.httpwatch.com/features.htm#filter
到
http://www.httpwatch.com/features.htm#print
浏览器并不会去重新请求页面,但是此操作会在浏览器的历史记录中添加一次记录,即你可以通过返回按钮回答上次的位置。这个特性对Ajax来说特别的有用,可以通过设置不同井号值,来表示不同的访问状态,并返回不同的内容给用户。(注:在IE6和IE7下井号的改变不会增加历史记录。)
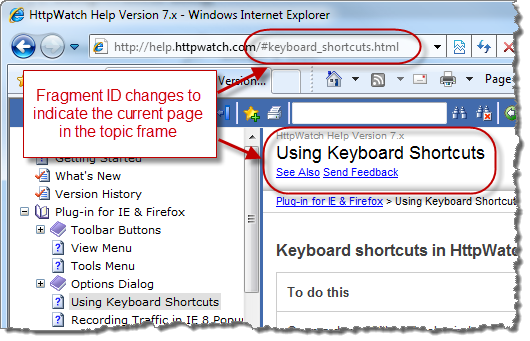
5、可以通过javascript使用window.location.hash来改变井号后面的值
window.location.hash这个属性可以对URL中的井号参数进行修改,基于这个原理,我们可以在不重载页面的前提下创造一天新的访问记录。如标记框架页面当前的页面:
除此之外,HTML 5新增的onhashchange事件,当#值发生变化时,就会触发这个事件。
6. Googlebot对井号的过滤机制
默认情况下Google在索引页面的时候会忽略井号后面的参数,同时也不会去执行页面中的javascript。然而谷歌为了支持对Ajax生成内容的索引,定义了如果在URL中使用“#!”,则Google会自动将其后面的内容转成查询字符串_escaped_fragment_的值。
比如最新的twitter URL:
http://twitter.com/#!/username
Google会自动请求
http://twitter.com/?_escaped_fragment_=/username
来获取Ajax内容。